Apache Spark is validated for use with Wasabi. Apache Spark is a fast and general-purpose cluster computing system. It provides support for streaming data, graphs, and machine learning algorithms to perform advanced data analytics.
Requirements
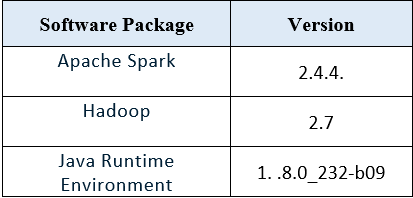
During testing, we used the following packages on a CentOS 7 server:
Install a few dependencies on the Spark system.
[root@ApacheSpark ~]# spark-shell --packages org.apache.hadoop:hadoop-aws:2.7.2In addition, you may need to download the following jar files into your "/spark-xxxx/jars" directory.
aws-java-sdk-1.7.4.jar
hadoop-aws-2.7.3.jarConfiguration Steps
Within the spark-shell command prompt, run the following commands (shown in Bold) using your Wasabi credentials and bucket information to connect to your Wasabi storage account. In the example below, we are using existing data in the bucket to read into the Spark cluster, and run analysis on.
scala> sc.hadoopConfiguration.set("fs.s3a.endpoint", "https://s3.wasabisys.com")scala> sc.hadoopConfiguration.set("fs.s3a.access.key","")scala> sc.hadoopConfiguration.set("fs.s3a.secret.key","")scala> val myRDD = sc.textFile("s3a:///")Note: The endpoint URL should be the URL associated with the region in which your bucket resides. Click here to find more information on the different Wasabi URLs.
At this point, you can run additional commands to run data analysis jobs as well as write the output to your S3 bucket as needed.
For example, see some commands executed below.
scala> myRDD.count
res3: Long = 25scala> myRDD.collectres4: Array[String] = Array(Bucket,BucketNum,StartTime,EndTime,NumBillableActiveStorageObjects,NumBillableDeletedStorageObjec ts,RawActiveStorageBytes,BillableActiveStorageBytes,BillableDeletedStorageBytes,NumAPICalls,IngressBytes,EgressBytes, e53b455 2a64c4afd-584aaa3a91f883d0-d0,333918,2020-01-13T00:00:00Z,2020-01-14T00:00:00Z,29,73,67013312,67042274,120692736,9,10475,4197 7, e53b4552a64c4afd-584aaa3a91f883d0-d0,333918,2020-01-12T00:00:00Z,2020-01-13T00:00:00Z,29,73,67013312,67042274,120692736,4, 4427,22785, e53b4552a64c4afd-584aaa3a91f883d0-d0,333918,2020-01-11T00:00:00Z,2020-01-12T00:00:00Z,29,73,67013312,67042274,120 692736,3,2965,14864, e53b4552a64c4afd-584aaa3a91f883d0-d0,333918,2020-01-10T00:00:00Z,2020-01-11T00:00:00Z,29,73,67013312,670 42274,120692736,3,2965,14864, e53b4552a64c4afd-...
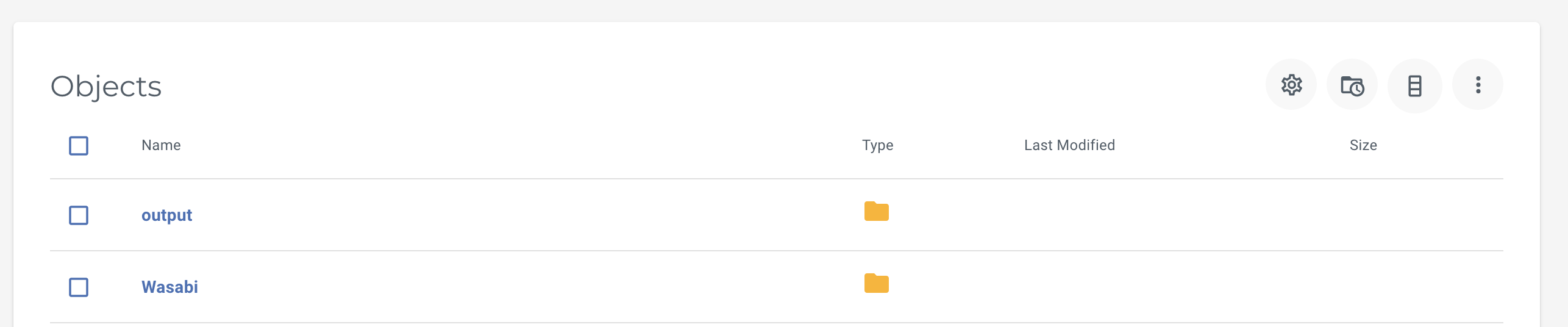
scala> myRDD.saveAsTextFile("s3a://sparktest/output")Note: The function count returns the number of elements in the RDD (Resilient Distributed Dataset), and collect returns an array that contains all of the elements in this RDD. The saveAsTextFile function saves this RDD as a compressed text file, using string representations of the elements, in a new folder called output inside the bucket sparktest. See screenshot below.