When managing buckets that have Object Lock enabled, you may find that some objects have retention periods set longer than needed, preventing deletion or modification. You can modify the Object Lock retention from the Wasabi Management Console. Updating retention dates across all object versions in a large bucket can be a time-consuming process. To simply that process, Wasabi developed a Python-based script to shorten retention periods. Both the Console and Python instructions are provided in this article.
Using the Console to Update the Retention Period
In the Bucket List, navigate to the bucket with the object for which you want to change the retention period.
Click on the Name of the object to display the File Details.
Click Edit in the Object Lock section.
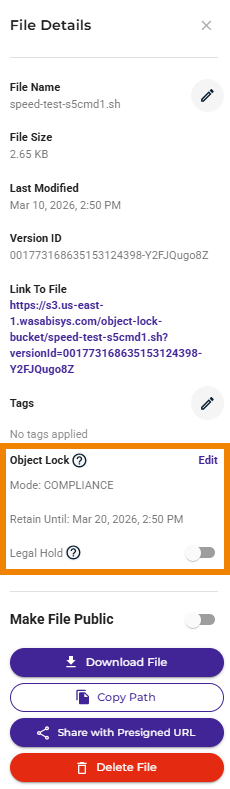
You can change the Object Lock mode. To change the retention period, enter a new date in the Retain Until area. Enter a date that is after the “minimal date,” which is displayed by default (Mar 20, 2026, in the example).

Click Apply.
Using a Python Script to Update the Retention Period
To simplify the process of updating retention dates across all object versions in a large bucket, Wasabi developed a Python script to:
Iterate through all objects (including non-current versions, if chosen) in a specified bucket
Update the retention date only on objects that are under retention (under Governance mode)
Save results to a CSV file (retention_update_results.csv)
Read and write a continuation_token.txt file to resume from the last position in case of interruption
Before using the Python script on a production bucket, it is highly recommended that you first test it on a non-critical or test bucket.
Requirements
Install the AWS CLI.
Configure the AWS CLI profile for the Wasabi account using the Wasabi keys.
Install Python 3.7+ to run the script.
Install required dependencies for the script using pip:
pip install boto3 aiohttp pandas botocore tqdm
Script Executions and Details
When executed, the script (available below) will:
Prompt you to enter your AWS CLI profile name (or press Enter to use the default).
Ask for the following input:
Your Wasabi bucket name
Region in which the bucket is created
Prefix (optional; leave blank to scan the whole bucket)
If you use a prefix, be sure to enter the FULL PREFIX PATH (for example, folder1/subfolder/) and do not include the bucket name or start with a forward slash.
New retention date in YYYY-MM-DD format
Indication to Include Deleted Versions. Select yes if you want to update retention for non-current versions; otherwise, select no.
The script sets the time to 12:00 AM UTC, which corresponds to 8:00 PM EDT on the previous day. For example, if the retention date for an object is set to April 17, 2028, and the retention period is reduced to April 16, 2028, the new retention date for the object will be April 15, 2028, at 8:00 PM EDT or April 16, 2028, at 12:00 AM UTC.
Python Script
The Python script is:
import boto3
import os
import asyncio
import aiohttp
from datetime import datetime
import pandas as pd
from botocore.config import Config
import json
import logging
from tqdm import tqdm
# Configure logging to print logs to console as well
logging.basicConfig(
level=logging.INFO,
format="%(asctime)s - %(levelname)s - %(message)s",
handlers=[
logging.FileHandler("execution.log"),
logging.StreamHandler() # Add console output
]
)
# Configure boto3 for parallel execution and retries
boto3_config = Config(
retries={"max_attempts": 3, "mode": "adaptive"}, # Increased retry attempts
max_pool_connections=100 # Increased parallel API calls
)
RECOVERY_FILE = "continuation_token.txt"
RESULTS_FILE = "retention_update_results.csv"
# Save and load continuation token for crash recovery
def save_continuation_token(token, batch_completed=False):
with open(RECOVERY_FILE, "w") as f:
json.dump({"continuation_token": token, "batch_completed": batch_completed}, f)
def load_continuation_token():
if os.path.exists(RECOVERY_FILE):
with open(RECOVERY_FILE, "r") as f:
data = json.load(f)
return data.get("continuation_token"), data.get("batch_completed", False)
return None, False
def save_results_to_csv(results):
df = pd.DataFrame(results, columns=["Status", "Key", "Filename", "VersionId", "Message"])
df.to_csv(RESULTS_FILE, mode='a', index=False, header=not os.path.exists(RESULTS_FILE))
logging.info(f"Saved {len(results)} results to CSV")
def create_s3_client(profile, region):
session = boto3.Session(profile_name=profile) if profile else boto3.Session()
endpoint_url = f"https://s3.{region}.wasabisys.com"
logging.info(f"Connecting to S3: {endpoint_url}")
return session.client("s3", region_name=region, endpoint_url=endpoint_url, config=boto3_config)
async def list_object_versions(s3_client, bucket_name, prefix, include_deleted, max_keys=1000, continuation_token=None):
paginator = s3_client.get_paginator("list_object_versions")
operation_params = {"Bucket": bucket_name, "Prefix": prefix, "MaxKeys": max_keys}
if continuation_token:
operation_params["ContinuationToken"] = continuation_token
page_iterator = paginator.paginate(**operation_params)
objects = []
next_token = None
try:
for page in page_iterator:
if "Versions" in page:
objects.extend([{ "Key": obj["Key"], "VersionId": obj["VersionId"] } for obj in page["Versions"]])
if include_deleted and "DeleteMarkers" in page:
objects.extend([{ "Key": obj["Key"], "VersionId": obj["VersionId"] } for obj in page["DeleteMarkers"]])
if "NextContinuationToken" in page:
next_token = page["NextContinuationToken"]
if len(objects) >= max_keys: # Stop when reaching max_keys
return objects[:max_keys], next_token
logging.info(f"Listed {len(objects)} objects in current batch.")
except Exception as e:
logging.error(f"Error listing versions: {e}")
return objects, next_token
async def get_object_retention_async(s3_client, bucket_name, object_key, version_id):
try:
response = await asyncio.to_thread(s3_client.get_object_retention, Bucket=bucket_name, Key=object_key, VersionId=version_id)
return response.get("Retention", {}).get("RetainUntilDate", "N/A")
except Exception as e:
logging.error(f"Error fetching retention for {object_key} - {version_id}: {e}")
return "N/A"
async def update_object_retention_async(s3_client, bucket_name, object_key, version_id, new_retention_date, current_retention_date):
try:
object_name = object_key.split('/')[-1]
new_retention_dt = datetime.strptime(new_retention_date, "%Y-%m-%d").date()
if isinstance(current_retention_date, datetime):
curr_retention_dt = current_retention_date.date()
elif current_retention_date != "N/A":
curr_retention_dt = datetime.strptime(current_retention_date, "%Y-%m-%dT%H:%M:%S%z").date()
else:
curr_retention_dt = datetime.min.date()
if curr_retention_dt > new_retention_dt:
await asyncio.to_thread(
s3_client.put_object_retention,
Bucket=bucket_name,
Key=object_key,
VersionId=version_id,
Retention={"Mode": "GOVERNANCE", "RetainUntilDate": datetime.strptime(new_retention_date, "%Y-%m-%d")},
BypassGovernanceRetention=True
)
logging.info(f"Updated retention for {object_key} - {version_id}")
return ("Success", object_key, object_name, version_id, "-")
else:
return ("Skipped", object_key, object_name, version_id, "Already retained longer")
except Exception as e:
logging.error(f"Failed to update {object_key} - {version_id} - Error: {str(e)}")
return ("Failed", object_key, object_name, version_id, str(e))
async def main():
logging.info("Starting retention update process...")
profile = input("Enter AWS CLI profile name (or press Enter for default): ").strip() or None
bucket_name = input("Enter your Wasabi bucket name: ").strip()
region = input("Enter your bucket region: ").strip()
prefix = input("Enter prefix (optional, press Enter to skip): ").strip() or ""
new_retention_date = input("Enter NEW retention date (YYYY-MM-DD): ").strip()
include_deleted = input("Include deleted versions? (yes/no): ").strip().lower() == 'yes'
s3_client = create_s3_client(profile, region)
continuation_token, batch_completed = load_continuation_token()
total_processed = 0 # Track processed objects
paginator = s3_client.get_paginator("list_object_versions")
operation_params = {"Bucket": bucket_name, "Prefix": prefix, "MaxKeys": 1000}
if continuation_token:
operation_params["ContinuationToken"] = continuation_token
page_iterator = paginator.paginate(**operation_params)
try:
for page in page_iterator: # Fetch and process one page at a time
object_versions = []
next_token = page.get("NextContinuationToken") # Correctly retrieve next token
num_versions = len(page.get("Versions", []))
num_delete_markers = len(page.get("DeleteMarkers", [])) if include_deleted else 0
total_objects_in_page = num_versions + num_delete_markers
logging.info(f"Processing Page - {num_versions} Versions, {num_delete_markers} DeleteMarkers, Total: {total_objects_in_page}")
# Collect object versions
if "Versions" in page:
object_versions.extend([{ "Key": obj["Key"], "VersionId": obj["VersionId"] } for obj in page["Versions"]])
# Collect delete markers if required
if include_deleted and "DeleteMarkers" in page:
object_versions.extend([{ "Key": obj["Key"], "VersionId": obj["VersionId"] } for obj in page["DeleteMarkers"]])
# Save next continuation token if available
save_continuation_token(next_token, batch_completed=False)
# If no objects found in the page, break
if not object_versions and next_token is None:
break
tasks = []
with tqdm(total=len(object_versions)) as pbar:
for obj in object_versions:
retention_date = await get_object_retention_async(s3_client, bucket_name, obj["Key"], obj["VersionId"])
task = asyncio.create_task(update_object_retention_async(
s3_client, bucket_name, obj["Key"], obj["VersionId"], new_retention_date, retention_date
))
task.add_done_callback(lambda _: pbar.update(1))
tasks.append(task)
results = await asyncio.gather(*tasks)
save_results_to_csv(results)
total_processed += len(object_versions)
logging.info(f"Processed {len(object_versions)} objects in this page. Total processed: {total_processed}")
save_continuation_token(next_token, batch_completed=True)
except Exception as e:
logging.error(f"Error during processing: {e}")
logging.info("Retention update process completed.")
if __name__ == "__main__":
asyncio.run(main())